700亿融资与永久降价背后,梁文锋的终极野心
出品|搜狐科技 作者|郑松毅 编辑|杨锦 近期AI圈的目光,再次聚焦在DeepSeek身上

出品|搜狐科技
作者|郑松毅
编辑|杨锦
近期AI圈的目光,再次聚焦在DeepSeek身上。
一边是传闻700亿元巨额融资进入收尾阶段,投前估值高达450亿美元,或将刷新国内科技初创企业单轮融资纪录;另一边,DeepSeek官宣旗舰模型API永久降价75%,直接把高端大模型调用成本压至行业地板价。
百亿资本争相入局,同行扎堆推出模型比排名、抢商业化订单,DeepSeek却选择坚持走最难走的路——不跟风、不急躁,技术长期开源,与全行业共享成果。
这种看似违背商业逻辑的操作,一度让市场难以看懂。直到《DeepSeek的10万亿美元宏伟战略》一文全网刷屏,外界才看清这家低调 AI 企业,早已不满足只做大模型服务商,而是在下一盘撬动十万亿美元产业的全局大棋。
腾讯、网易、京东争相入局,DeepSeek逆向降价比GPT便宜12倍
本轮700亿元融资,堪称近年国内AI领域分量最重的资本豪赌。
据网传融资结构,腾讯、国智投、砺思资本已悉数参投,宁德时代、网易、京东等产业资本也在深度洽谈。创始人梁文锋拟个人出资约200亿元,占本轮融资规模的近四成。

和多数科创企业急于向资本市场描绘盈利前景不同,DeepSeek态度十分明确:优先底层技术攻坚,暂缓商业化变现,全力深耕通用人工智能研发。
很多人好奇,为何坚称“不受外界干扰”的DeepSeek如今会风向大变接受融资?
杜克大学电子与计算机工程系杰出教授陈怡然对搜狐科技说出了业内的普遍看法:“融资很正常,但不是因为缺钱,核心是为了留住人才。如果没有市场公认的估值,员工的股权就没有具体的价值体现,高薪被其他公司挖走是很现实的事,光靠情怀很难长期有作用。平衡情怀和现实利益,是任何一家科技公司发展到一定阶段都要面对的问题。”
既然开放了融资,以DeepSeek的影响力为何不干脆继续抬高融资额?
洪泰基金合伙人、洪泰智造创始人兼CEO乔会君向搜狐科技分析,“百亿美元的估值确实不算高,核心就是参考另外国内三家AI企业(智谱、Minimax、月之暗面)。没把第一轮融资额抬得更高,是为后面的投资人留出空间。”
“这轮融资本质是用‘低额度+高门槛+强条款’筛选合拍的投资人,排除短视逐利型机构。很可能DeepSeek在一年内会进行多轮融资,像Kimi不到半年,估值从40亿美元涨到了180亿美元。DeepSeek的估值也可能在短期内飞涨。”
乔会君认为,业内都在争抢投资名额,主动权已经不在投资方而在DeepSeek,现实是大多数(投资方)根本没机会投。
与融资消息同步落地的,是5月 23 日的定价调整。DeepSeek 将 V4-Pro 旗舰模型2.5折价格永久固化,输入(缓存命中)低至 0.025元/百万tokens,输入(缓存未命中)3元、输出仅6元,价格不足GPT-4o的十二分之一,相比智谱 GLM、通义千问等国产旗舰也极具性价比。

当前全球高带宽内存供给紧张、算力成本居高不下,多数AI厂商都谨慎保价守利,唯有 DeepSeek逆势降价。这样做的目的很明确:通过低价降低开发者使用门槛,引流收集高质量数据,从而反哺模型迭代,达成正向循环的同时先行拿下行业话语权。
梁文锋的终极野心,十万亿级AI硬件生态棋局?
外界始终疑惑,DeepSeek为何放着多模态等热门赛道不卷,放着快速变现的应用路径不走,反而死磕底层算法、坚持全面开源?
刷屏长文给出答案:DeepSeek的终极战场从来不在表层应用,而在被海外卡脖子的AI硬件底层。
目前看来,DeepSeek所有架构迭代与算法创新,都围绕一个核心目标:用算法突破大模型对天价内存的依赖,并为国产存储、AI芯片等玩家创造成长空间。
很多人好奇,DeepSeek究竟把算法优化到了什么程度?
文内提到的一组关键KV缓存数据足以见真章:同样是1M超长上下文场景,DeepSeek V4仅需4.14GB HBM,而GLM-5需要102.28 GB HBM,Qwen-3.6-27B需要61.04 GB HBM。
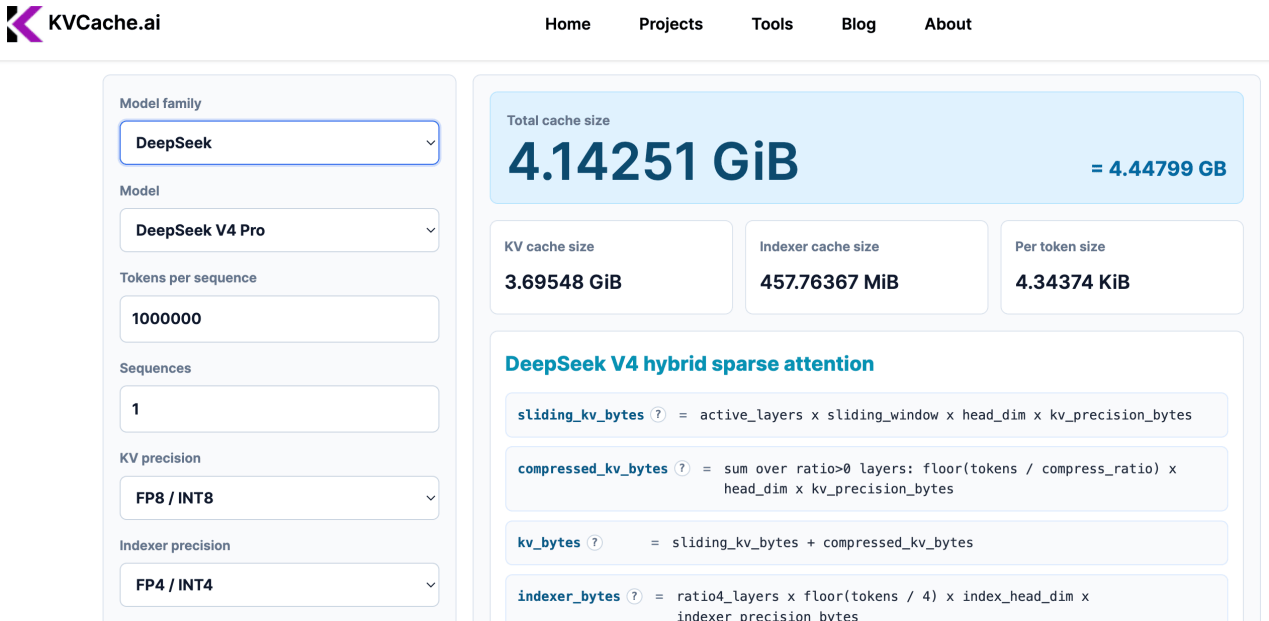
事实上,同等上下文KV缓存占用越小越好,推高推理速度的同时,单卡能容纳更多对话上下文,稳定性也会更好。而这份成绩背后,离不开DeepSeek做出的MoE混合专家架构、GRPO强化学习算法、MLA/DSA/CSA 注意力压缩、mHC流形约束超连接等一系列原创突破。
目前,DeepSeek的MLA、DSA等核心技术已被智谱GLM、月之暗面Kimi等同行采用,并坚持技术开源,助力国内AI打破海外生态垄断。
具体来看,DeepSeek的算法优化路径恰好弥补了国内高端芯片生产短板,充分释放包括长鑫LPDDR、长江存储3D NAND等国产成熟存储的产能优势。原本依赖海外高端芯片才能运行的AI大模型,如今可依托国产内存、SSD闪存完成训练与推理。
业内存在预判,不排除DeepSeek借鉴OpenAI与AMD的深度绑定模式,与国内硬件巨头深度结盟。至此,DeepSeek将不再依靠API服务费赚取短期收益,而是以行业标准制定者身份,赚取产业链的长期红利,有望孵化出十万亿美元规模的全球AI硬件生态,且自身估值向万亿美元级别靠拢。
在行业看来,DeepSeek的终极野心,从来不是打造一款对标GPT的大模型,而是构建中国自主可控的AI生态。在全球AI激烈竞争格局中,梁文锋如何下完这盘大棋,还有待时间检验。